SERVICE サービス

LLM診断
リスクを管理して、価値あるAI運用を支える
ポルトが解決できる課題
こんなお悩みはありませんか?
- 意図しない動作や不適切な回答をさせられないか不安
- プロンプトが出力されてしまい、悪用されないか心配
サービス概要
OWASP TOP 10 for LLMの診断観点を基に、大規模言語モデル(LLM)の出力・挙動に起因するリスク対する調査を行います。
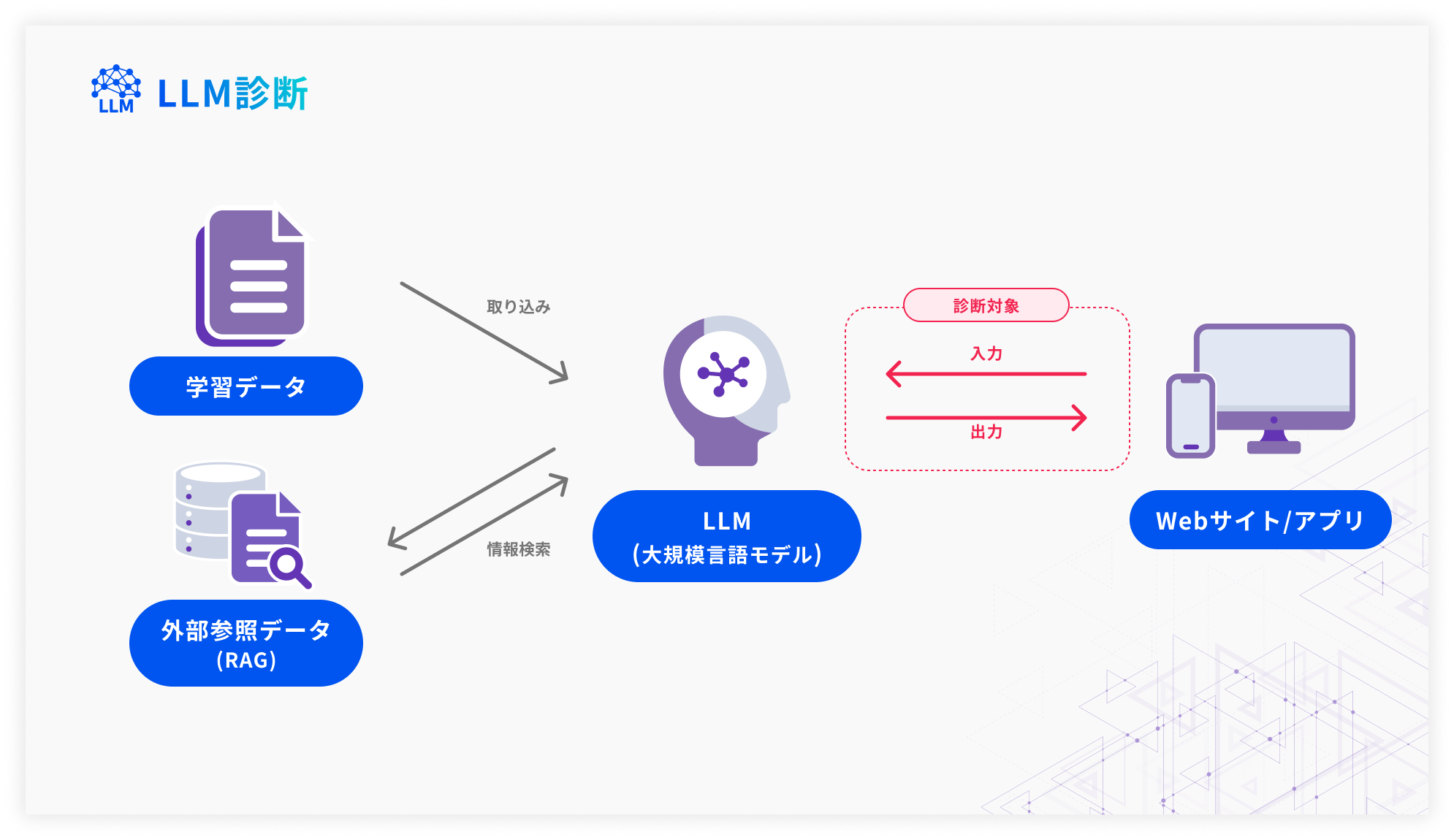
大規模言語モデル(LLM)の入出力を検証し、隠れたリスクを可視化します。
実効性のある改善提案で安全かつ価値あるLLM活用を支援します。
サービスの特徴
経験豊富なエンジニアによる実践的な診断
業種やサービスの特性を理解した上で、最適な診断手法を用いてセキュリティリスクを検証します。
また、セキュリティに詳しくない方でも理解できるよう、検出された脆弱性によってどのようなリスクが発生する可能性があるのかを分かりやすく説明します。
OWASP TOP 10 for LLMの観点に基づいた診断
プロンプトインジェクション、機密情報の漏洩、過剰な権限付与といった脅威に対し、従来Webアプリ診断では見抜けない深いリスクを調査します。
診断観点
OWASP TOP 10 for LLMの診断観点を基に、大規模言語モデル(LLM)の出力・挙動に起因するリスクに対する調査を行います。
| 脆弱性名 | 項目 | 概要 |
|---|---|---|
| プロンプトインジェクション | 直接型 | ユーザー入力がプロンプトにそのまま組み込まれ、悪意ある命令が実行される脆弱性 |
| 間接型 | システムプロンプトや過去対話の履歴を通じて、命令の意図が改変される問題 | |
| 機密情報の開示 | 偶発的な情報漏洩 | 設定ミスや例外処理により、機密情報が意図せず出力・エラーに含まれる脆弱性 |
| 意図的な抽出 | 攻撃者が巧妙な入力を繰り返し、段階的に非公開情報を引き出す問題 | |
| 不適切な出力処理 | 検証不足による出力 | モデル出力の検証が不十分で、誤情報・攻撃的内容がそのまま使用される脆弱性 |
| フィルタリングの不備 | 出力に危険なコードや命令が含まれ、ユーザーが意図せず実行してしまう問題 | |
| システムプロンプトの漏洩 | 直接的な漏洩 | システムプロンプトそのものが出力され、利用者に知られる脆弱性 |
| 間接的な漏洩 | エラーメッセージや出力断片を通じて、システムプロンプトの一部が推測される問題 |
業務の流れ
お見積もり
- 当社作業
-
- NDA締結
- 診断対象確認
- 対象一覧作成
- 貴社作業
-
- NDA締結
- 診断環境準備
- データ作成
発注
- 当社作業
-
- 見積書送付
- 診断期間調整
- 貴社作業
-
- 発注内容確認
- 発注書送付
診断
- 当社作業
-
- 環境確認
- 脆弱性診断
- 貴社作業
-
- 発注内容確認
- 発注書送付
報告書
- 当社作業
-
- 脆弱性精査
- 証跡確保
報告会
- 当社作業
-
- 必要に応じて実施
※現地開催の場合は、オプション料金
- 必要に応じて実施
納品
- 当社作業
-
- 報告書送付
- 請求書送付
- 貴社作業
-
- 報告書確認および検収
再診断
- 当社作業
-
- 再診断無料
※現地開催の場合は、オプション料金
- 再診断無料
- 貴社作業
-
- 脆弱性診断修正
- 診断環境準備
関連する診断サービス
よくある質問
一般的には、サービス公開前や大きな機能追加・改修のタイミングでの実施が推奨されています。
また、運用中のサービスでも定期的に診断を行うことで、新たに発見された脆弱性や設定変更によるリスクを早期に発見することができます。
基本的には、本番環境と同じ構成の診断用環境(検証環境)での実施を推奨しています。
脆弱性診断では疑似攻撃を行うため、本番環境で実施するとデータベースの不整合やサーバーへの負荷など、予期しない影響が発生する可能性があります。
安全に診断を行うためにも、診断用の環境をご用意いただくことを推奨しています。
診断費用は、各サービスの違いに基づく見積りと、見積方法に基づく違いがあります。
◯Webアプリ/API診断
・画面遷移図からの概算見積り
診断対象が開発前や開発途中で場合である場合、処理がわかる遷移フローや全体の画面遷移図から見積りを行います。
想定される機能や処理から、1画面のリクエスト数を想定しお見積りします。
・クローリングによる見積り
クローリングと呼ばれるサイト巡回作業により、診断対象のリンクやボタンを押下し、HTTPリクエスト(通信)数をカウントします。
データ登録・更新処理などを中心に、診断の優先度の高いリクエストを選定し、お見積りします。
◯CMS診断/プラットフォーム診断など
・ドメイン単位でのお見積り
ドメイン数×スキャン実行数を元にお見積りします。
診断で検出された脆弱性は、再現手順と合わせて、修正方法・推奨される対策をまとめた報告書を作成いたします。
実際の修正作業は、報告書をご参考にお客様の開発チームにて行っていただきます。
また、修正後の「再診断」は1度まで無料でご案内しております。